
Introdução
Este artigo examina uma série de experimentos que utilizaram a criação de vídeos curtos e imagens em movimento com aparência orgânica e manual, adotando Inteligência Artificial (IA) com modelos generativos para estudar processos de transferência de estilos com imagens de difusão. Durante esses experimentos, abordamos conceitos como as possibilidades criativas de geração de imagem por IA, a interface entre texto e imagem, questões de autoria, treinamento de modelos com imagens autorais e de uso em domínio público, além do emprego de plataformas de código aberto. Embora o campo esteja em rápida evolução, algumas das reflexões apresentadas podem ter caráter atemporal.
A incorporação de imagens de dança como matriz da imagem confere maior expressividade e um caráter poético aos experimentos. A complexidade do movimento humano reforça a dimensão orgânica dos trabalhos, com as contribuições das artistas Taianne Lobo e Helena Bevilaqua. Este enfoque destaca as possibilidades de exploração do movimento como forma de expressão visual. São experimentos que resultam em videodança, onde é possível pensar em diálogos entre o movimento e esta nova tecnologia e a expressão visual das imagens. A utilização de um enquadramento único foi um recurso para observar e evidenciar esta relação.
Inicialmente, o objetivo era criar animações baseadas em vídeos, buscando um resultado gestual e observando um nicho onde as ferramentas de tratamento em computação gráfica não tinham sucesso. Filtros raramente produzem resultados orgânicos suficientes. Por esse motivo, processos como rotoscopia, pinturas sequenciadas e desenhos digitais foram utilizados nas últimas décadas, demandando considerável esforço humano. Exemplos como o All Over de Paula Toller e Donavon Frankenreiter (1), realizado pela Comparsas Comunicação, assim como a abertura da novela O Pai Ó (2) feita pelo Grupo Sal, ambos com pinturas de André Côrtes e Marcelo Gemmal, destacam essas abordagens como referência. O primeiro experimento, denominado MOVE, funcionou como um teste, ainda em um ambiente de teste de código e a partir da pergunta: como seria criar uma peça audiovisual utilizando um modelo de IA e imagens como guia. No segundo experimento,CORES, abordamos o emprego de imagens tridimensionais e render através de IA. Utilizamos captura de movimento, animação 3D e tratamento da imagem para um pré-processamento da imagem. Apontamos ainda algumas características particulares da colaboração entre animação 3D e imagem por difusão.
Em GESTOS, o terceiro experimento, a solução proposta buscou personalizar as características visuais das imagens, trazendo um conjunto de imagens autorais para treinar. Desse modo, os resultados poderiam ser fruto de um diálogo generativo entre imagens autorais e vídeo, reduzindo o trabalho intensivo do desenho quadro a quadro, ao mesmo tempo em que preservava a aparência manual característica personalizada. Para isso, envolveu a transferência de estilo, em que um modelo adicional foi treinado para transformar um vídeo de referência de forma generativa. Inconsistências entre os quadros foram deliberadamente exploradas, transformando-se em elementos expressivos e parte integrante da linguagem visual.
The workflows chosen were based on the vid-to-vid technique, Os fluxos de trabalho escolhidos basearam-se na técnica vid-to-vid, ainda utilizando sequências de imagem, e em transferência de estilo. Isto é, temos vídeos como referência do movimento, assim como o prompt de texto, e em seguida apontamos como essas imagens devem ser apresentadas, com uma gama infinita de opções. As imagens foram geradas com base no modelo Stable Diffusion (3) em ferramentas de código aberto ou de uso gratuito, como o Blender (4) . A exceção é a utilização do Adobe After Effects para tratamento dos vídeos de entrada e finalização das sequências de vídeo de entrada e de saída. Existe uma tentativa de usar o sistema da maneira mais transparente possível, o que evita o efeito "caixa preta"(5), buscando uma profundidade maior que o input-output. A opção por treinar o modelo fundamentou-se em experiências paralelas de treinamento com desenhos autorais e geração de imagens estáticas, de artistas como Mario Klingemann (6), Refik Anadol (7) e Remi Molettee(8), além deste artigo de Manovich (9), o qual aponta artistas que utilizam aprendizagem de máquina dentro de seus fluxos de trabalho.
O Stable Diffusion(10) é um modelo que gera imagens através de um processo conhecido como difusão de imagens a partir de um espaço latente – uma rede de relações entre formas e significados codificados. Esse espaço é criado a partir do treinamento em grandes quantidades de imagens classificadas e associadas a textos, adicionando ruído. Com base nessa relação texto-imagem, novas imagens são geradas progressivamente por meio de uma distribuição inicial de ruído aleatório. Esse processo pode ser comparado a espalhar areia sobre um papel coberto de cola – a areia se fixa apenas nas áreas adesivas. No contexto do modelo, a "cola" é representada pela probabilidade de acerto, combinada a parâmetros como referências textuais (prompts) e imagens fornecidas como entrada.
Esse método permite resultados consistentes e ajustáveis, criando uma triangulação de pesos entre as imagens de referência, o modelo utilizado e o prompt, isto é, o texto que descreve as imagens a serem geradas. Ainda não se alcançou uma solução definitiva neste estudo, entretanto, os experimentos realizados e os registros obtidos promovem reflexões sobre os processos de geração de imagem por difusão, abrindo caminhos para futuras explorações e melhorias.
Experimentos
1. MOVE

Nesse experimento, foi criada uma micrometragem de dança (Fig. 01) utilizando IA para gerar quadros com base em um vídeo-guia. O trabalho contou com uma coreografia executada e criada por Taianne Lobo (Fig. 02), que inspirou a utilização do trabalho de Wassily Kandinsky (11). A partir dessa interpretação, entre forma do movimento, com referências abertas como Balé Triádico da Bauhaus (12), de Oskar Schlemmer foi elaborado o prompt. Foram realizados vários testes em imagens estáticas para formular o prompt, combinando descrições como " beautiful color geometric figures" e "watercolor by Kandinsky", onde se buscam as formas e técnicas desejadas para o preenchimento semi aleatório da forma de vídeo.
Aqui, a inconsistência no movimento, com imagens geradas a cada quadro em contraste com o movimento em câmera lenta, criou um efeito visual diferente, mas interessante de rotoscopias procedurais, em que se pinta e desenha cada quadro. Faz-se necessário notar que a combinação de câmera lenta e taxa de quadros alta é extremamente difícil de ser realizada manualmente.
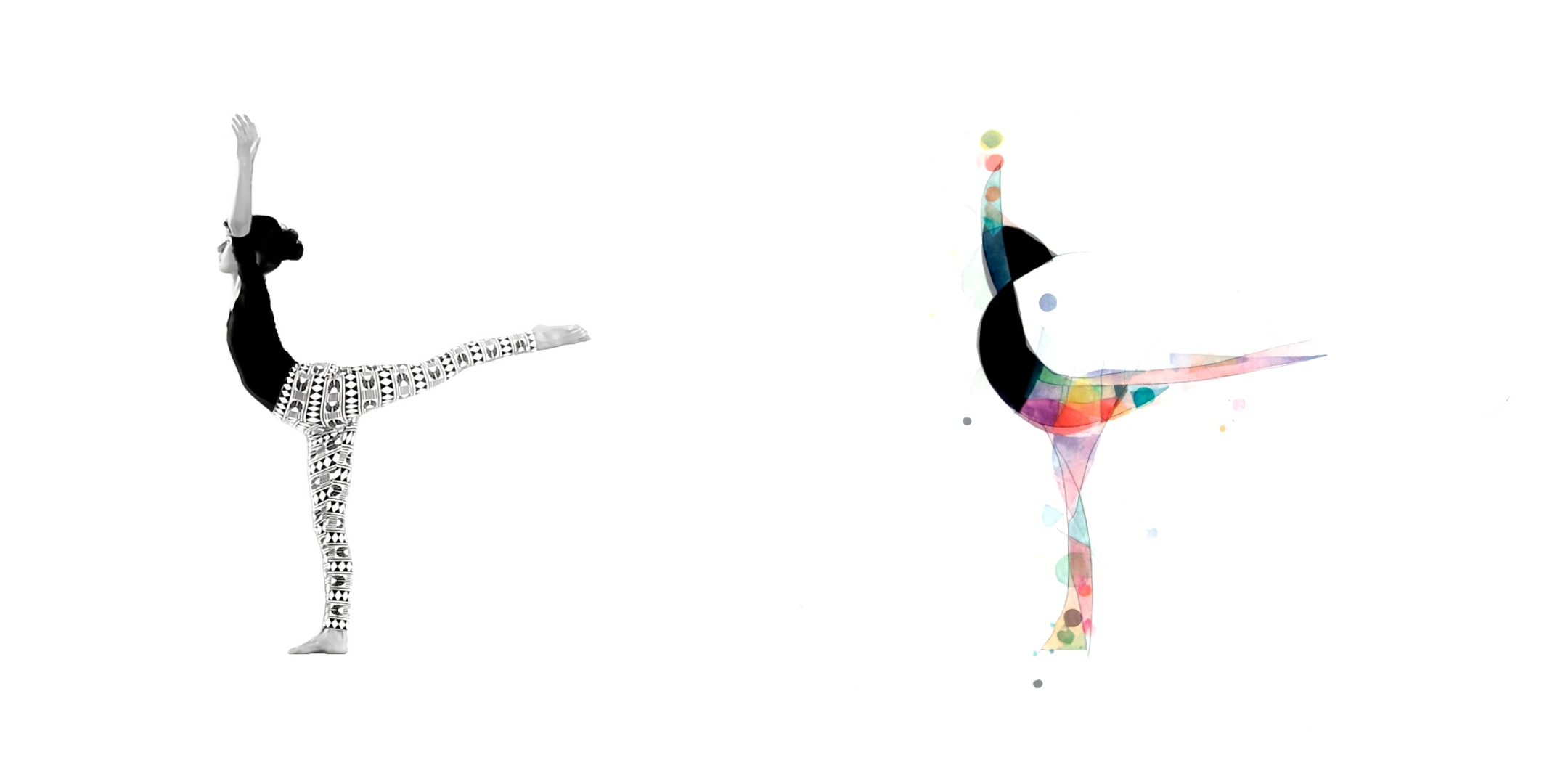
O experimento se aproxima de um sampling. O resultado é novo perante as duas fontes de imagem, não sendo uma colagem, na qual, dessa forma, verifica-se o efeito da construção da imagem, misturando as entradas de dados através do modelo de difusão. Cabe ressaltar a legalidade da escolha da fonte, uma vez que a obra de Kandinsky está em domínio público.
O Deforum Stable Diffusion (13), uma ferramenta baseada em Stable Diffusion 1.5, voltada para a criação de animações, foi utilizado para gerar as imagens. A implementação foi realizada no Google Colab Research, uma plataforma colaborativa que permite a execução de códigos e modelos de IA. A execução do processo envolveu configurações precisas de prompts textuais e ajustes nos parâmetros de geração, como seed fixo para consistência dos quadros. A sincronização e a edição das imagens foram feitas no Adobe After Effects, no qual texturas e outros elementos foram adicionados.
A micrometragem foi exibida em festivais como FILE (14), InShadow (15), London International Screendance Festival (16) e Zinetika Festival (17), onde foi um dos premiados.
2.CORES

O segundo experimento, “Cores”, utilizou os movimentos capturados da performance de Helena Bevilaqua, que foi registrada no Laboratório Visgraf do IMPA (pode ser visto no texto “Ocean Dance”). O material foi editado no Blender para criar animações tridimensionais, posteriormente estilizadas com IA no Stable Diffusion XL através do Fable (18), um programa de motion design. O processo envolveu a utilização de recursos como ecotemporal na animação tridimensional para criar um efeito de rastro, que foi interpretado pela IA como textura pictórica (Fig. 03) . Cabe citar a referência desse ecotemporal, recurso utilizado por Norman Mclaren no filme Pas de Deux (19). No caso deste experimento buscamos reproduzir um rastro para ser explorado em abstração. O prompt "Colorful Suminagashi Marbling" em alguns momentos produziu texturas semelhantes às de pintura a óleo (Fig. 04), de certo modo, alucinando. Uma alucinação de IA ocorre quando um sistema cria informações incorretas ou inventa detalhes, porque seu treinamento foi incompatível à solicitação do usuário. Nesse caso parece que faltavam dados de marmorização com fundo liso. Embora nem sempre o resultado correspondesse exatamente à descrição, a coesão estética foi mantida. Na sequência, também foi aplicado o modelo animatediff (20) para criar consistência entre os quadros (Fig. 05).

Além disso, a manipulação de volumes tridimensionais facilita a capacidade de o modelo IA compreender formas, possibilitando novas interpretações estilísticas. A sinergia entre mocap, modelagem 3D e ferramentas generativas é possivelmente um modo de condução da forma da imagem generativa.

3.GESTOS
Este experimento trata de um processo semelhante aos anteriores, com a principal diferença de que foi treinado um modelo específico autoral para produzir as imagens. Dessa forma, foi reunido um conjunto de cerca de 70 imagens (Fig. 06) com a intenção de criar um estilo para a geração de tais imagens. A performance de Taianne Lobo foi utilizada como referência de imagem em movimento.

Assim como os anteriores, combinou performances de dança filmadas com imagens geradas pelo Stable Diffusion, porém nesse experimento foi empregada a versão XL (SDXL), e com a interface Comfy UI (21). Este último é uma interface modular destinada a modelos de difusão, que apresenta o fluxo de construção das imagens e possibilita experimentar diferentes configurações.

Nesse ambiente, o modelo SDXL foi ajustado via LoRA (22) (Low-Rank Adaptation). Essa técnica permite ajuste fino de modelos generativos para treinamento adicional.
Foram gerados testes estáticos para testar o treinamento, observar como o estilo se aplicava. Inicialmente apenas com prompt (Fig. 07) e em seguida guiada por um quadro extraído do material filmado (Fig. 08)

Para uma leitura mais precisa da imagem filmada, foram utilizados recursos de ControlNet e modelos integrados para estrutura do corpo e profundidade da imagem. Nesse contexto, o Midas Depth Map(23) foi empregado para capturar a profundidade, enquanto o DWpose(24) assegurou que as proporções corporais permanecessem fieis à filmagem original. Esses elementos permitiram que o estilo visual, mesmo com um acabamento aguado, mantivesse consistência nas proporções do corpo, enquanto a paleta de cores era derivada do modelo previamente treinado, garantindo coesão estética. Foram testados modelos de consistência, usados para evitar o batimento entre os frames, em sequências de vídeo, mas a aparência se tornava mais artificial, pois o batimento é algo natural nessa técnica e contém uma nuance de imprecisão.
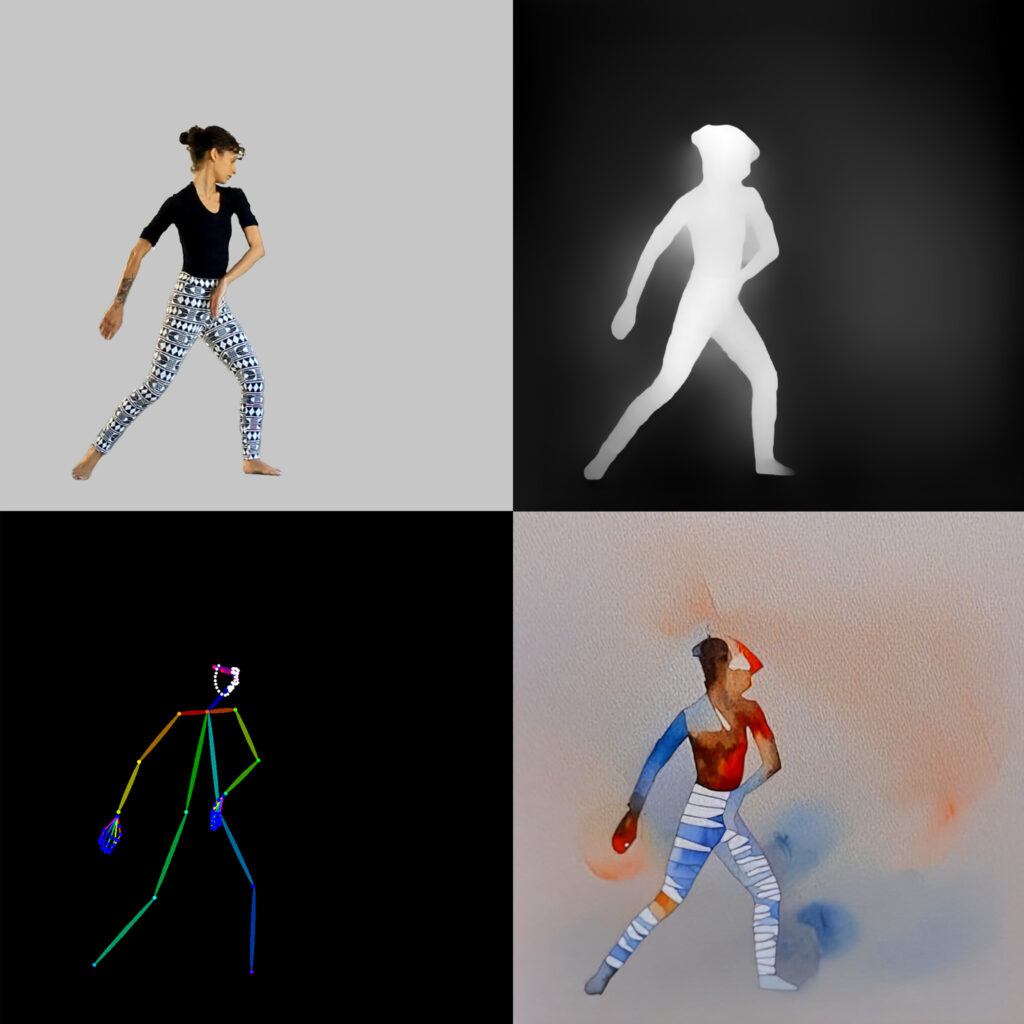
O processo incluiu etapas de recorte das filmagens por rotoscopia no Adobe After Effects e a geração de imagens com prompts ajustados. A escolha das imagens de entrada, com fundo cinza, influenciou diretamente o resultado final. Pequenos testes com sequências curtas de quadros permitiram otimizar o fluxo antes da geração completa.
Considerações
Os experimentos parecem demonstrar que técnicas generativas utilizando IA e técnicas procedurais de criação de imagem podem ser complementares. A transferência de estilo, combinada com treinamento, através de ferramentas como Comfy UI permite que, muito além de adotar estilos existentes, estes sejam personalizados, empregando os modelos de IA como ferramenta para diminuição do esforço. Isso só é possível através do uso de certos métodos para manter a gestualidade e originalidade.
Treinamentos direcionados e personalizados podem atender melhor às necessidades específicas de cada projeto ou mesmo ter domínio das características das imagens a serem geradas. Ainda existem tópicos a serem aprofundados, como treinamento, controle, sistematização dos processos e até mesmo da criação direcionada de imagens específicas para o tratamento, formulando o resultado. Existe um sentido de balanço de pesos entre o modelo original, o treinamento adicional e as imagens-guia que podem ser compreendidas para resultados mais precisos.
Os modelos de imagem frequentemente têm dificuldade em compreender arte e cultura locais de forma tão eficaz quanto estilos amplamente conhecidos, como o de Kandinsky, porque têm seu treinamento enviesado, em geral, retirado da internet, o que reflete múltiplos vieses da sociedade. Considerando que esses modelos geram imagens com base em referências prévias, pode ser interessante desenvolver treinamentos específicos utilizando conjunto de dados em domínio público que contemplem conteúdo cultural pertinente, valorizando e promovendo maior representatividade de cultura e arte não dominante. A partir dessas experiências, em especial da última descrita, é possível pensar em designers, artistas e ilustradores criando modelos para gerar imagens e vídeos. Trabalhos de geração a partir de acervos e conjunto de obras, como a experiência realizada com a obra de Kandinsky, podem ser realizados com treinamento adicional.
A combinação de animação e modelos tridimensionais com IA pode facilitar o controle da geração de IA e, por outro lado, potencializar o render com elementos fotográficos ou figurativos. Algumas ferramentas de análise de imagem através de IA, como mapa de profundidade ou análise do corpo humano, têm evoluído e possuem propriedades que podem ser úteis em um render direto a partir do Blender.
A geração de imagens por difusão representa uma nova forma de criação digital, distinta de desenhos, filmes ou fotografias. Ferramentas e processos empregados exercem influência no resultado final, evidenciando como as escolhas tecnológicas moldam o produto criativo. Por esse modo, existe um novo campo de estudos das características dessas imagens. Certamente as ferramentas irão evoluir e se transformar, mas a estrutura de treinamento e geração de imagens deve se manter. Dentro desse contexto é interessante pensar na intencionalidade e olhar crítico como ferramentas que podem orientar desde o prompt de texto, até treinamento ou desenvolvimento específico.
A percepção de movimento através do sequenciamento de imagens precedeu os modelos de vídeo, assim como o desenvolvimento do cinema analógico é posterior à criação da sensação de movimento através de desenhos e fotos sequenciadas. A exploração híbrida entre IA, fotos, vídeos, animação 3D e práticas manuais abre novos caminhos para expressões visuais, incentivando a reflexão sobre o papel do design no futuro da imagem digital.
O presente trabalho foi realizado com apoio da Coordenação de Aperfeiçoamento de Pessoal de Nível Superior – Brasil (CAPES) – Código de Financiamento 001.
Referências
[1] Paula Toller All Over (Feat. Donavon Frankenreiter). , 6 abr. 2020. Disponível em: . Acesso em: 27 jan. 2025
[2] Ó Paí, Ó. Disponível em: . Acesso em: 27 jan. 2025.
[3] ROMBACH, R. et al. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv, , 13 abr. 2022. Disponível em: . Acesso em: 5 fev. 2025.
[4] FOUNDATION, B. blender.org – Home of the Blender project – Free and Open 3D Creation Software. blender.org, [s.d.]. Disponível em: . Acesso em: 5 fev. 2025.
[5] FLUSSER, V. Filosofia da caixa preta : ensaios para um futura filosofia da fotografia. [s.l.] Annablume, 2011.
[6] Memories of Passersby I | Quasimondo. , [s.d.]. Disponível em: . Acesso em: 5 fev. 2025.
[7] Refik Anadol. Available at: <https://refikanadol.com/>. Accessed on: 5 Feb. 2025.
[8] Remi (@Remi_molettee) | Foundation. Available at: <https://foundation.app/@Remi_molettee?tab=collections>. Accessed on: 18 Jan. 2024.
[9] MANOVICH, L. ‘Make it New’: GenAI, Modernism, and Database Art. [n.d.].
[10] ALAMMAR, J. The Illustrated Stable Diffusion. Available at: <https://jalammar.github.io/illustrated-stable-diffusion/>. Accessed on: 5 Feb. 2025.
[11] Wassily Kandinsky – 614 artworks, biography, books, quotes, articles. Available at: <https://www.wassilykandinsky.net/>. Accessed on: 5 Feb. 2025.
[12] SCHLEMMER, O.; MOHOLY-NAGY, L.; MOLNÁR, F. The theatre of the Bauhaus. Translated by Arthur S. Wensinger. Zurich: Lars Müller Publishers, 2020.
[13] deforum-art/deforum-stable-diffusion. deforum-art, , 18 Jan. 2024. Available at: <https://github.com/deforum-art/deforum-stable-diffusion>. Accessed on: 18 Jan. 2024
[14] Bernardo Alevato & Taianne Oliveira | FILE FESTIVAL. Available at: <https://file.org.br/anima_2023/bernardo-alevato-e-taianne-oliveira-move/>. Accessed on: 5 Feb. 2025.
[15] Edition 2023. Available at: <https://www.inshadowfestival.com/edicao-2023>. Accessed on: 5 Feb. 2025.
[16] 2023 Programme 4. Available at: <https://www.screendancelondon.com/2023-programme-4-lisdf>. Accessed on: 5 Feb. 2025.
[17] VIII. Edition 2023. Available at: <https://www.zinetikafestival.com/es/festival/ediciones/2023/films/move>. Accessed on: 5 Feb. 2025.
[18] Fable Prism: Where designers control generative AI. , 19 Mar. 2024. Available at: <https://www.youtube.com/watch?v=3h2hpClc5Mg>. Accessed on: 7 Feb. 2025
[19] pas de deux. National Film Board of Canada, , 1968. Available at: <https://www.youtube.com/watch?v=WopqmACy5XI>
[20] GUO, Y. et al. AnimateDiff: Animate Your Personalised Text-to-Image Diffusion Models without Specific Tuning. arXiv, , 8 Feb. 2024. Available at: <http://arxiv.org/abs/2307.04725>. Accessed on: 7 Feb. 2025
[21] comfyanonymous/ComfyUI: The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface. Available at: <https://github.com/comfyanonymous/ComfyUI?tab=readme-ov-file>. Accessed on: 7 Feb. 2025.
[22] HU, E. J. et al. LoRA: Low-Rank Adaptation of Large Language Models. arXiv, , 16 Oct. 2021. Available at: <http://arxiv.org/abs/2106.09685>. Accessed on: 7 Feb. 2025
[23] RANFTL, R. et al. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer. arXiv, , 25 Aug. 2020. Available at: <http://arxiv.org/abs/1907.01341>. Accessed on: 7 Feb. 2025
[24] YANG, Z. et al. Effective Whole-body Pose Estimation with Two-stages Distillation. arXiv, , 25 Aug. 2023. Available at: <http://arxiv.org/abs/2307.15880>. Accessed on: 7 Feb. 2025



