
Introduction
This article examines a series of experiments that used the creation of short videos and moving images with an organic and manual appearance, adopting Artificial Intelligence (AI) with generative models to study style transfer processes with broadcast images. During these experiments, we addressed concepts such as the creative possibilities of image generation by AI, the interface between text and image, issues of authorship, training models with copyright and public domain images, and the use of open source platforms. Although the field is rapidly evolving, some of the reflections presented may be timeless.
The incorporation of dance images as the image matrix gives the experiments greater expressiveness and a poetic character. The complexity of human movement reinforces the organic dimension of the works, with contributions from artists Taianne Lobo and Helena Bevilaqua. This approach emphasizes the possibilities of exploring movement as a form of visual expression. These are experiments that result in video dance, where it is possible to consider links between movement, this new technology and also the visual expressions of the images. The use of a single frame was a resource for observing and highlighting this relationship.
Initially, the aim was to create animations based on videos, looking for gestural results and observing a niche where computer graphics processing tools were unsuccessful. Filters rarely produce sufficiently organic results. For this reason, processes such as rotoscoping, sequenced paintings and digital drawings have been used in recent decades, requiring considerable human effort. Examples such as Paula Toller and Donavon Frankenreiter’s All Over(1), produced by Comparsas Comunicação, as well as the opening of the soap opera O Pai Ó(2) by Grupo Sal, both with paintings by André Côrtes and Marcelo Gemmal, highlight these approaches as a reference. The first experiment, called MOVE, worked as a test, still in a code testing environment and based on the question: what would it be like to create an audiovisual piece using an AI model and images as a guide? In the second experiment, CORES, we approached the use of three-dimensional images and rendering through AI. We used motion capture, 3D animation and image processing to pre-process the image. We also pointed out some characteristics of the collaboration between 3D animation and diffusion imaging.
In GESTOS, the third experiment, the proposed solution sought to customize the visual characteristics of the images by bringing in a set of Isto seria authorial pictures to train on. In this way, the results could be the result of a generative dialogue between images and video, reducing the intensive work of frame-by-frame drawing, while preserving the manual appearance of the custom feature. This involved style transfer, in which an additional model was trained to generatively transform a reference video. Inconsistencies between frames were deliberately exploited, becoming expressive elements and an integral part of the visual language.
The workflows chosen were based on the vid-to-vid technique, still using image sequences, and on style transfer. In other words, we have videos as a reference for movement, as well as the text prompt, and then we indicate how these images should be presented, with an infinite range of options. The images were generated using the Stable Diffusion model (3) in open source or free tools such as Blender (4). The exception is the use of Adobe After Effects to process the input videos and post producing output video sequences. There is an attempt to use the system in the most transparent way possible, which avoids the “black box” effect(5) , seeking a greater depth than the input-output. The choice to train the model was based on parallel training experiences with authorial drawings and still image generation by artists such as Mario Klingemann (6), Refik Anadol (7) and Remi Molettee(8), as well as this article by Manovich(9) [9], which points out artists who use machine learning in their workflows.
Stable Diffusion(10) is a model that generates images through a process known as image diffusion from a latent space – a network of relationships between shapes and coded meanings. This space is created by training on large quantities of labeled images associated with texts, adding noise. Based on this text-image relationship, new images are generated progressively through an initial distribution of random noise. This process can be compared to spreading sand on a piece of paper covered in glue – the sand only sticks to the adhesive areas. In the context of the model, the “glue” is represented by the probability of getting it right, combined with parameters such as tension, textual references (prompts) and images provided as input.
This method allows for consistent and adjustable results, creating a triangulation of weights between the reference images, the model used and the prompt, i.e. text describing the images to be generated. A definitive solution has not yet been reached in this study, however, the experiments carried out and the records obtained promote reflection on the processes of image generation by diffusion, opening a new path for future exploration and improvement.
Experiments
1. MOVE

In this experiment, a dance micro movie (Fig. 01) was created using AI to generate frames based on a video guide. The work included a choreography performed and created by Taianne Lobo (Fig. 02), which inspired the use of Wassily Kandinsky’s work (11). The prompt was based on this interpretation, between form and movement, with open references such as Oskar Schlemmer’s Triadic Ballet of the Bauhaus (12). Various tests were carried out on still images to formulate the prompt, combining descriptions such as “beautiful colour geometric figures” and “watercolor by Kandinsky”, where the desired forms and techniques are sought for the semi-random filling of the video form.
Here, the inconsistency in movement, with images generated every frame in contrast to the slow-motion movement, has created a different but interesting visual effect from procedural rotoscoping, in which each frame is painted and drawn. Certainly, the combination of slow motion and high frame rate is extremely difficult to execute manually.
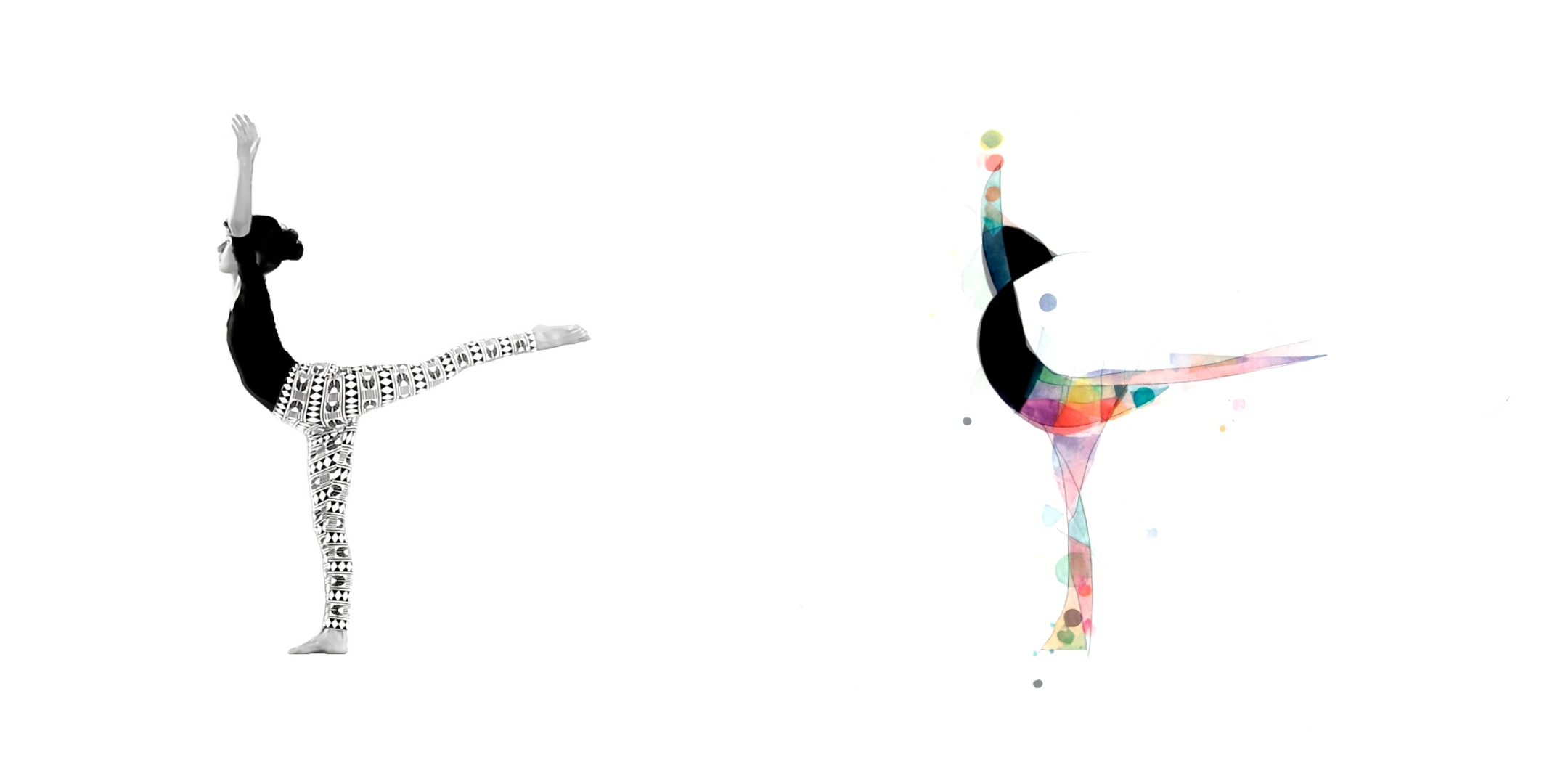
The experiment is akin to sampling. The result is new in relation to the two image sources and is not a collage, thus verifying the effect of image construction by mixing the data inputs through the diffusion model. It is worth emphasizing the legality of the choice of source, since Kandinsky’s work is in the public domain.
Deforum Stable Diffusion (13), a tool based on Stable Diffusion 1.5 for creating animations, was used to generate the images. The implementation was carried out on Google Colab Research, a collaborative platform that allows AI codes and models to be run. Executing the process involved precise configurations of textual prompts and adjustments to the generation parameters, such as a fixed seed for frame consistency. The images were synchronized and edited in Adobe After Effects, where textures and other elements were added.
The micro movie was shown at festivals such as FILE (14), InShadow (15), London International Screendance Festival (16) and Zinetika Festival (17), where it was one of the winners.
2.CORES

The second experiment, “CORES”, used the movements captured from Helena Bevilaqua’s performance, which was recorded at IMPA’s Visgraf Laboratory (you can see it in the text “Ocean Dance”). The material was edited in Blender to create three-dimensional animations, which were then stylized with AI in Stable Diffusion XL using Fable (18), a motion design software. The process involved using resources such as echo in the three-dimensional animation to create a trail effect, which was interpreted by the AI as a pictorial texture (Fig. 03). It is worth mentioning the reference of this echo, a resource used by Norman Mclaren in the film Pas de Deux (19). In the case of this experiment, we sought to reproduce a trail to be explored in abstraction. The “Colourful Suminagashi Marbling” prompt sometimes produced textures like oil paintings (Fig. 04), in a hallucinating way. An AI hallucination occurs when a system creates incorrect information or makes up details because its training was inconsistent with the user’s request. Although the result didn’t always correspond exactly to the description, the aesthetic cohesion was maintained, enriching the project. This “mistake” was probably the result of the plain background, something unlikely in marbling technique. Next, the animatediff model (20) was also applied to create consistency between the frames (Fig. 05).

In addition, the manipulation of three-dimensional volumes facilitates the AI model’s ability to understand shapes, making new stylistic interpretations possible. The synergy between mocap, 3D modelling and generative tools is possibly a way of driving the form of the generative image.

3.GESTOS
This experiment is a similar process to the previous ones, with the main difference being that a specific authorial model was trained to produce the images. In this way, a set of around 70 images (Fig. 06) was assembled with the intention of creating a style for generating these images. Taianne Lobo’s performance was used as a moving image reference.

Like the previous ones, it combined filmed dance performances with images generated by Stable Diffusion, but in this experiment the XL version (SDXL) was used, and with the Comfy UI interface (21). The latter is a modular interface designed for diffusion models, which shows the flow of image construction and allows you to experiment with different configurations.

In this environment, the SDXL model was adjusted via LoRA (22) (Low-Rank Adaptation). This technique allows generative models to be fine-tuned for further training.
Static tests were generated to test the training and see how the style applied. Initially only with a prompt (Fig. 07) and then guided by a frame taken from the filmed material (Fig. 08).

For a more accurate reading of the filmed image, ControlNet resources and integrated models for body structure and image depth were used. In this context, Midas Depth Map (23) was used to capture the depth, while DWpose (24) ensured that the body proportions remained faithful to the original footage. These elements allowed the visual style, even with a watery finish, to maintain consistency in the body proportions, while the colour palette was derived from the previously trained model, ensuring aesthetic cohesion. Consistency models, used to avoid the beat between frames, were tested in video sequences, but the appearance became more artificial, as the beat is something natural in this technique and contains a nuance of imprecision.
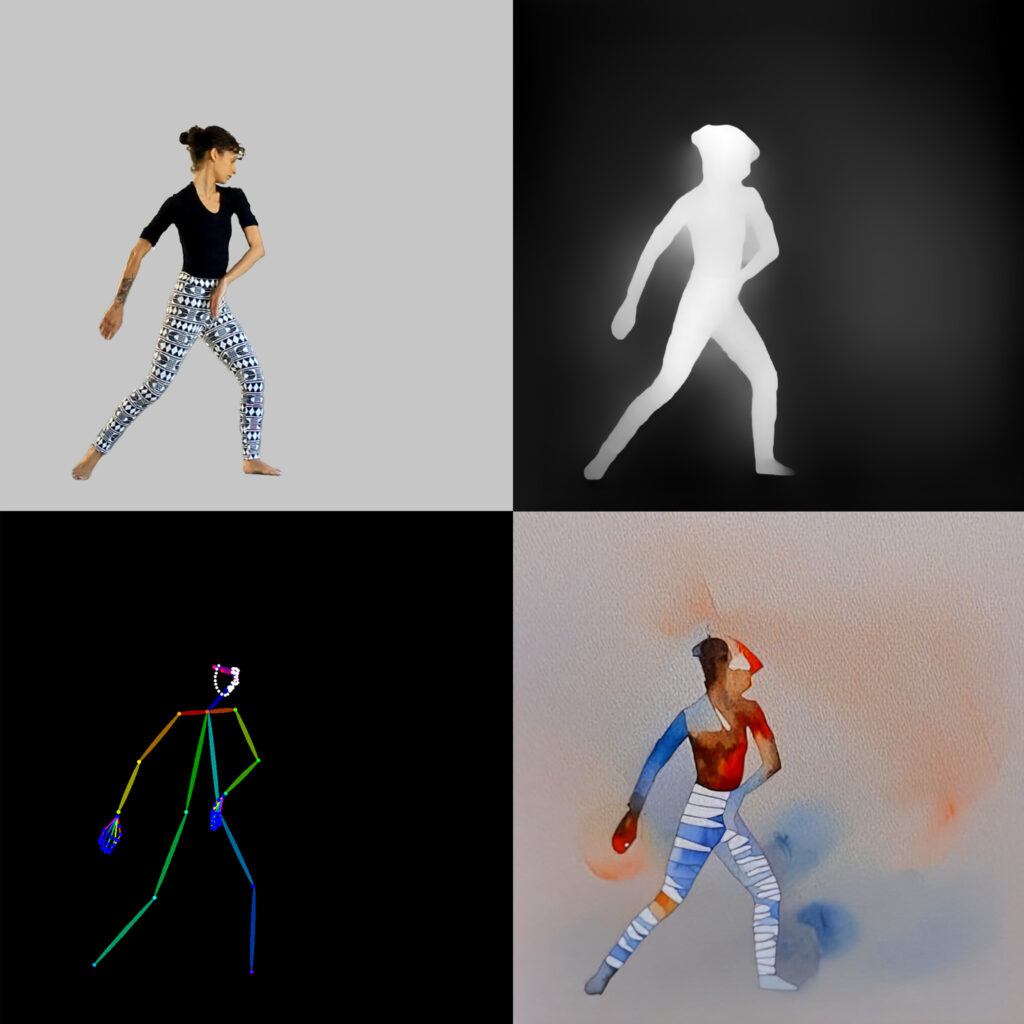
The process included stages of cropping the footage using rotoscoping in Adobe After Effects and generating images with adjusted prompts. The choice of input images, with grey backgrounds, directly influenced the result. Small tests with short sequences of frames made it possible to optimize the flow before complete generation.
Considerations
The experiments seem to show that generative techniques using AI and procedural image creation techniques can be complementary. Style transfer, combined with training, through tools such as Comfy UI, allows existing styles to be personalized far beyond adopting them, using AI models as a tool to reduce effort. This is only possible by using certain methods to maintain gestures and originality.
Targeted and personalized training can better meet the specific needs of each project or even master the characteristics of the images to be generated. There are still topics to be explored in greater depth, such as training, control, systematization of processes and even the targeted creation of specific images for treatment, formulating the result. A balance is maintained between the original model, the additional training, and the guide images, which facilitates a more accurate understanding and results.
Image models often struggle to understand local art and culture as effectively as widely known styles, such as Kandinsky’s, because they are biased in their training, usually taken from the internet, which reflects multiple societal biases. Considering that these models generate images based on previous references, it may be interesting to develop specific training using public domain datasets that include pertinent cultural content, valuing and promoting greater representation of non-dominant culture and art. Based on these experiences, especially the last one described, it is possible to think of designers, artists and illustrators creating models to generate images and videos. Generation work based on collections and sets of works, such as the experiment carried out with Kandinsky’s work, can be carried out with additional training.
Combining animation and three-dimensional models with AI can make it easier to control AI generation and, on the other hand, enhance rendering with photographic or figurative elements. Some AI image analysis tools, such as depth mapping or human body analysis, have evolved and have properties that can be useful in a direct render from Blender.
The generation of images by diffusion represents a new form of digital creation, distinct from drawings, films or photographs. The tools and processes used have an influence on the result, showing how technological choices shape the creative product. As a result, there is a new field for studying the characteristics of these images. The tools will certainly evolve and change, but the structure of training and image generation must remain the same. Within this context, it’s interesting to think of intentionality and a critical eye as tools that can guide everything from the text prompt to specific training or development.
The perception of movement through the sequencing of images preceded video models, just as the development of analogue cinema followed the creation of the sensation of movement through drawings and sequenced photos. The hybrid exploration between AI, photos, videos, 3D animation and manual practices opens new avenues for visual expression, encouraging reflection on the role of design in the future of the digital image.
This work was carried out with the support of the Coordination for the Improvement of Higher Education Personnel – Brazil (CAPES) – Funding Code 001.
References
[1] Paula Toller All Over (Feat. Donavon Frankenreiter). , 6 Apr. 2020. Available at: <https://www.youtube.com/watch?v=w4EvaUZ5SX0>. Accessed on: 27 Jan. 2025
[2] Ó Paí, Ó. Available at: <https://gruposal.com.br/portfolio/o-pai-o/>. Accessed on: 27 January 2025.
[3] ROMBACH, R. et al. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv, , 13 Apr. 2022. Available at: <http://arxiv.org/abs/2112.10752>. Accessed on: 5 Feb. 2025
[4] FOUNDATION, B. blender.org – Home of the Blender project – Free and Open 3D Creation Software. blender.org, [s.d.]. Available at: <https://www.blender.org/>. Accessed on: 5 Feb. 2025
[5] FLUSSER, V. Black box philosophy: essays for a future philosophy of photography. [s.l.] Annablume, 2011.
[6] Memories of Passersby I | Quasimondo. , [n.d.]. Available at: <https://underdestruction.com/2018/12/29/memories-of-passersby-i/>. Accessed on: 5 Feb. 2025
[7] Refik Anadol. Available at: <https://refikanadol.com/>. Accessed on: 5 Feb. 2025.
[8] Remi (@Remi_molettee) | Foundation. Available at: <https://foundation.app/@Remi_molettee?tab=collections>. Accessed on: 18 Jan. 2024.
[9] MANOVICH, L. ‘Make it New’: GenAI, Modernism, and Database Art. [n.d.].
[10] ALAMMAR, J. The Illustrated Stable Diffusion. Available at: <https://jalammar.github.io/illustrated-stable-diffusion/>. Accessed on: 5 Feb. 2025.
[11] Wassily Kandinsky – 614 artworks, biography, books, quotes, articles. Available at: <https://www.wassilykandinsky.net/>. Accessed on: 5 Feb. 2025.
[12] SCHLEMMER, O.; MOHOLY-NAGY, L.; MOLNÁR, F. The theatre of the Bauhaus. Translated by Arthur S. Wensinger. Zurich: Lars Müller Publishers, 2020.
[13] deforum-art/deforum-stable-diffusion. deforum-art, , 18 Jan. 2024. Available at: <https://github.com/deforum-art/deforum-stable-diffusion>. Accessed on: 18 Jan. 2024
[14] Bernardo Alevato & Taianne Oliveira | FILE FESTIVAL. Available at: <https://file.org.br/anima_2023/bernardo-alevato-e-taianne-oliveira-move/>. Accessed on: 5 Feb. 2025.
[15] Edition 2023. Available at: <https://www.inshadowfestival.com/edicao-2023>. Accessed on: 5 Feb. 2025.
[16] 2023 Programme 4. Available at: <https://www.screendancelondon.com/2023-programme-4-lisdf>. Accessed on: 5 Feb. 2025.
[17] VIII. Edition 2023. Available at: <https://www.zinetikafestival.com/es/festival/ediciones/2023/films/move>. Accessed on: 5 Feb. 2025.
[18] Fable Prism: Where designers control generative AI. , 19 Mar. 2024. Available at: <https://www.youtube.com/watch?v=3h2hpClc5Mg>. Accessed on: 7 Feb. 2025
[19] pas de deux. National Film Board of Canada, , 1968. Available at: <https://www.youtube.com/watch?v=WopqmACy5XI>
[20] GUO, Y. et al. AnimateDiff: Animate Your Personalised Text-to-Image Diffusion Models without Specific Tuning. arXiv, , 8 Feb. 2024. Available at: <http://arxiv.org/abs/2307.04725>. Accessed on: 7 Feb. 2025
[21] comfyanonymous/ComfyUI: The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface. Available at: <https://github.com/comfyanonymous/ComfyUI?tab=readme-ov-file>. Accessed on: 7 Feb. 2025.
[22] HU, E. J. et al. LoRA: Low-Rank Adaptation of Large Language Models. arXiv, , 16 Oct. 2021. Available at: <http://arxiv.org/abs/2106.09685>. Accessed on: 7 Feb. 2025
[23] RANFTL, R. et al. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer. arXiv, , 25 Aug. 2020. Available at: <http://arxiv.org/abs/1907.01341>. Accessed on: 7 Feb. 2025
[24] YANG, Z. et al. Effective Whole-body Pose Estimation with Two-stages Distillation. arXiv, , 25 Aug. 2023. Available at: <http://arxiv.org/abs/2307.15880>. Accessed on: 7 Feb. 2025



