
Generative models have transformed the landscape of creative technology, introducing novel methods that continually redefine artistic boundaries. A pivotal advancement in this field is the integration of models in their embedding space, enabling a seamless translation of text into images and offering nuanced control over the result. In our experimentation, we adopt a straightforward approach: connect the output of one generative model to the input of another, giving rise to various types of data such as text, audio, image, and video from a single user input. These connections form a directed graph of models, composing a multi-modal model [Figure 1]. Our initial proof-of-concept, which utilizes fixed connections [Figure 5], sets the stage for the development of a graphic tool that allows users to generate their own multi-modal models. This is the blueprint of a remarkable creativity tool.
1 INTRODUCTION
In the evolving landscape of digital artistry, multi-modal generative models stand at the forefront of innovation, reshaping the way artists conceive and execute their creative visions. This paper delves into the intersection of these generative models, where text, audio, visual, and video elements are not just juxtaposed but intricately interwoven to create a new artistic lexicon. By exploring the fusion of these modalities, we uncover the immense potential for a more nuanced, dynamic, and expressive form of digital art. This synthesis not only broadens the creative canvas but also challenges and redefines traditional notions of artistic creation, heralding a new era in digital artistry where boundaries are constantly being reimagined and expanded. [Figure 1]
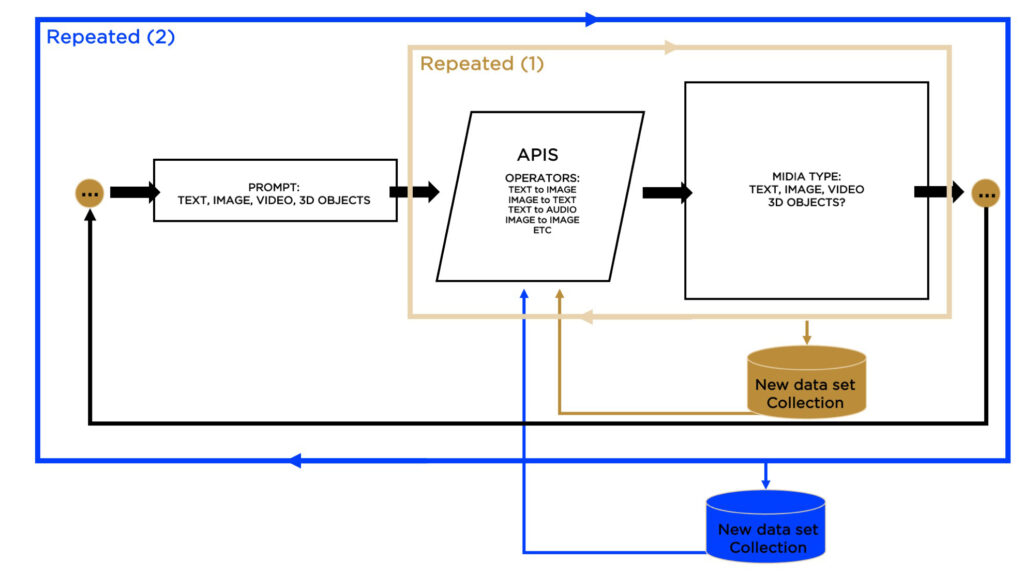
This diagram illustrates the iterative process where a user prompt initiates the creation of diverse media types via a series of API operations, culminating in a new dataset collection. The cycle depicted shows how text, images, videos, and potentially 3D objects undergo transformation, showcasing the pipeline’s capability for expansive data generation and iterative refinement.
2 OBJECTIVES
• Enhanced Creativity and Flexibility: By linking different types of generative models (text, audio, image, and video), users can create complex, multi-modal content from a single input. This approach significantly expands the creative possibilities, allowing for the generation of diverse outputs from a consistent conceptual basis.
• Potential for User-Generated Model Structures: The idea of a graphic tool that allows users to generate their own multi-modal models opens up possibilities for personalized and user-specific applications. It could lead to new ways of interacting with AI and creating content, tailored to individual needs and preferences.
• Development of a Multi-Modal Model Graph: The concept of a directed graph of models composing a multi-modal model is innovative. It suggests an interconnected system where the output of one model directly feeds into the input of another, creating a seamless flow of data transformation.
• Exploring Multimodal Generative Pipelines in the Metaverse: Investigate the capabilities of inter- connected generative models to create a versatile, multimodal pipeline within the metaverse environment. This exploration aims to utilize the power of AI to transform single user inputs, enhancing the immersive and creative potential of virtual worlds. Leveraging interconnected generative AI models into UNITY Sentis to establish a versatile, multimodal pipeline in the metaverse, particularly exploring the LunaPark Metaverse [VFXRio 2023]
(https://www.spatial.io/s/LunaPark-2-0-64cfeb874d4710ef26ea9066)
• Experimentation and Research: From a research perspective, this approach provides a platform for exploring the relationships between different types of data and understanding how information is transformed across modalities.
• Simulate AI Data Influx: Examine the impact on data models learning from and reprocessing synthetic media across multiple generations.
• Broadening the Scope of AI Creative Applications: Propel the integration of AI into diverse creative arenas, emphasizing the development of a multi-faceted collaborative platform. This will involve crafting novel interfaces and ecosystems where AI and human creativity converge, fostering a breeding ground for innovative artistic expressions. The objective is to leverage the adaptive and generative prowess of AI, transcending traditional boundaries to encompass interactive gaming, performative arts, and co-creative storytelling within enriched multimedia experiences.
• Streamlining Content Creation: This method can explore different data types.
3 AI IMAGERY AND PHILOSOPHICAL DISCOURSE: WITTGENSTEIN + FOUCAULT
The perceptual interpretation of AI-generated art can be enriched by contrasting philosophical perspectives, particularly those of Wittgenstein and Foucault. Wittgenstein’s ’language game theory’ [Wikipedia 2023a] [Wittgenstein 1953] em- phasizes context in language, pivotal for AI prompt interpretation, suggesting that meanings evolve with contemporary usage. This aligns directly with AI’s text or image prompts, where meanings shift based on current linguistic contexts. Concurrently, Foucault’s analysis of representation, as seen in his interpretation of Magritte’s work “Ceci n’est pas une pipe” [Foucault 2008], underscores the distinction between reality and its portrayal, a critical factor in understanding AI art. Together, these philosophies offer a comprehensive framework for categorizing and comprehending AI-generated imagery, blending theoretical insights with modern technological advancements.
4 THE DYNAMIC INTERPLAY OF ARTIST, ART OBJECT, AND USER IN AI: THE INTERACTIVE SYMPHONIES
• The Artist as Artist-Observer: In multimodal AI art, the artist is both the creator and an active participant in the evolving art experience. This duality reflects Wittgenstein’s language game theory, where the meaning and interpretation of an artwork, like language, are not fixed but evolve through interaction and context. The artist-observer’s role parallels the AI’s function in generative models, where it both creates and modifies content based on ongoing input, blurring the traditional roles of creator and observer.
• The Dynamic Art Object: The art object in multimodal AI is akin to Foucault’s interpretation of Magritte’s painting. Just as the painting “Ceci n’est pas une pipe” [Wikipedia 2023b] challenges our perception of rep- resentation versus reality, the AI-generated art object transcends traditional boundaries. It’s not merely a static representation but an interactive, evolving entity. This dynamic nature of the art object in AI challenges traditional notions of art, mirroring the philosophical debates on the nature and meaning of language and representation.
• The User as an Active Participant: The role of the user in this context is critical. No longer just a passive observer, the user becomes an active participant in the art experience. Their interactions with the art object directly influence its evolution. This reflects Wittgenstein’s view on the context-dependent nature of language and meaning. Just as the meaning of words can change based on usage and context, the art object in AI changes and evolves with user interaction, making the art experience highly personalized and variable.
5 EXPERIMENTATION WITH MIDJOURNEY
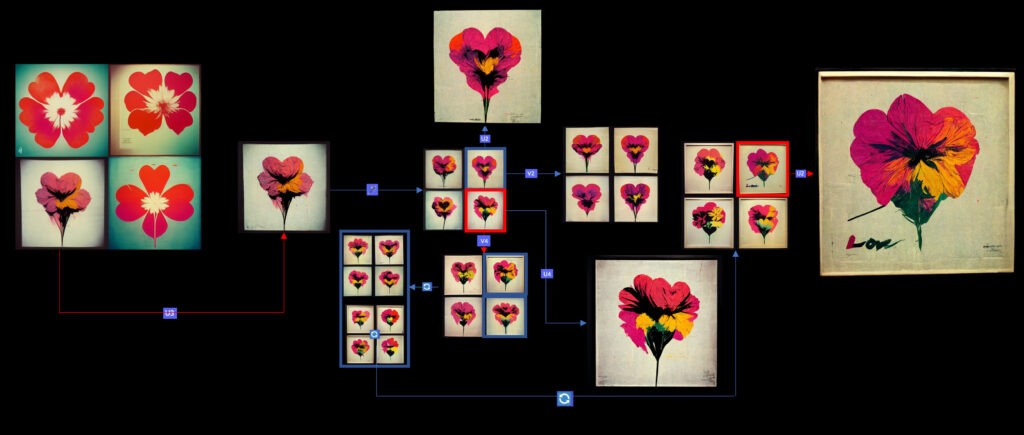
This visual sequence depicts the generative evolution of flower imagery inspired by Andy Warhol’s iconic style, initiated by a MidJourney prompt. Reflective of genetic processes, the series starts with basic floral forms, which through iterative variations and combinations, exhibit emergent features such as hearts and textual elements. The final iteration, akin to the rare manifestation of a recessive gene, reveals a complex image where the flowers form a heart shape, accompanied by the word ’Love’, symbolizing the culmination of the generative journey.
The research commenced with an experimental engagement with Midjourney (Version 3, Oct – 2022), a sophisticated generative AI tool. This model is designed to produce a set of four images in response to textual prompts, showcasing an advanced level of photorealism and deep linguistic comprehension. The procedural framework (using midjourney as a multimodal IMAGE to IMAGE from a specific textual starting point) allows for multiple interactions with the generated content. The user, or ’creator,’ has the option to request an alternate set of four images (variations) or to select an existing image for ’upscaling’ to a higher resolution. A distinctive feature of this process is the ’generative evolution’ leading to an interactive development of a preferred image [Figure 2] . This is achieved applying 2 key functionalities:
• ’Variations’ (V): prompting the model to synthesize a new set of four images based on the amalgamation of the initial prompt
• ’Upscale’ (U): designed to enhance the resolution and detail of a generated image.
In this interactive dynamic, the AI operates solely on the inputs from a single prompt contributing to the evolving nature of the generated imagery. This process is akin to iterative genetic variation and selection. For instance, in the series titled ’Love Machine,’ part of the ’I Want To Be a Machine’ collection [Figure 2], the evolutionary progression of a Flower image is observed. The series started with a simple set of 4 flowers, which underwent numerous transformations through continuous upscaling and variations modifications, analogous to adding genetic information and developing recessive genes.
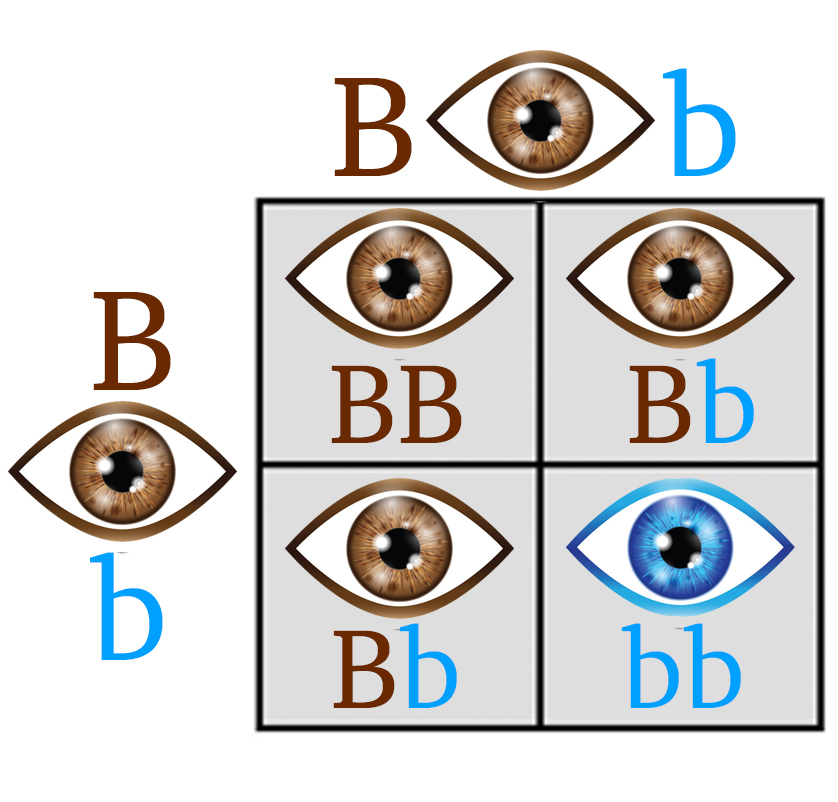
The evolution of the imagery can be compared to a genetic analogy where, for example, the crossing of brown-eyed individuals (Bb x Bb) with a dominant trait can result in a recessive blue-eyed offspring (bb). Further crossing of this blue-eyed variant with a family carrying dominant genes (bb x Bb) leads to a diverse offspring, mirroring the prompt-driven evolution in the AI model. In the context of the Flower imagery, this process resulted in a spectrum of variations, ultimately leading to the incorporation of hearts and the word ’love’ in the final iteration, much like the emergence of unexpected traits in a genetic cross. [Figure 3] In summary, this exploration highlights the model’s capacity for ’generative evolution,’ the prompt’s syntax is crucial. It encapsulates the weights of a probabilistic model, instructions, and parameters for the AI, guiding how features like hearts and text (“love”) are developed in the sequence of images. Revealing the exact syntax of the prompt would essentially disclose the ’formula’ behind the specific image transformations, demonstrating how each element in the prompt contributes to the final visual output. This aspect underscores the importance of the prompt in shaping the AI’s creative process, acting in this case as a replicable key for generating consistent sequences in image evolution shown on [Figure 3].

(a) Initial Generative Set: This image, produced by MidJourney in response to a specific prompt, showcases an initial set of four distinct flowers that were re-ordered to serve as an illustrative parallel to reflect the stages of AI-driven generative evolution with a clear nod to the DNA explanation provided. Each new iteration presented three dominant specimens alongside one recessive variant.
(b) Genetic Cross Diagram: Representing a genetic analogy, this diagram illustrates the cross of brown-eyed individuals carrying a recessive gene for blue eyes (Bb x Bb), leading to 1/4 probability of blue-eyed offspring (bb). This genetic process mirrors the AI model’s development, where iterative crossings result in unexpected traits, akin to the emergence of hearts and the word ’love’ in the final flower imagery, as depicted in the AI-generated sequence.
6 ROLE OF THE PROMPT
The prompt in this context serves as a specific key that, when input again, can recreate similar variations of the original image. This is comparable to using a password to access a set of related yet distinct outcomes.
7 INITIAL MOTIVATION FOR THIS RESEARCH
Potential implications of the increasing prevalence of synthetic media, particularly AI-generated art, on the internet:
• As AI art becomes more common, the role and impact of reprocessing synthetic media across multiple generations on data models, it will be added to the vast database of images of new data sets that was previously dominated by human-made creations. This influx of synthetic media could significantly alter the “noise” The concern is that future AI-generated art will be more influenced by previous
• AI creations than by original human artwork. This shift could have profound effects on the nature and quality of AI art and Human collective imagery. The model described in [Figure 1] can be used to simulate this process. These include the creation of data echo chambers, catastrophic forgetting, overfitting, feedback loops, degradation in creativity, and the impact of low-quality generated data. The right assessment would involve carefully considering these factors and developing new strategies.
7.1 THE MONALISA PICASSO EFFECT
The potential degradation of human artistic references over time. For example, when AI is prompted to create an artwork like “Mona Lisa in the style of Picasso,” it may increasingly refer to synthetic interpretations of Picasso’s style rather than Picasso’s actual works. This could lead to outputs that are less representative of Picasso’s style, as they are based on iterative AI interpretations rather than the original art. This issue highlights a crucial aspect of AI development in the field of art: the need to carefully consider the sources of training data and the potential long-term impacts of relying heavily on AI-generated content. [Figure 4]
This artwork, a product of MidJourney’s generative AI and first-generation upscaling, serves as a pivotal study in the data influx project. It represents an imaginative re-interpretation of Leonardo da Vinci’s Mona Lisa, restyled in the abstract, cubist manner of Pablo Picasso. This piece is not just an artistic fusion but also a crucial part of initial research exploring the impact datainflux of artistic data sets on generative model outputs.
8 THE FIRST MULTIMODAL GENERATIVE PIPELINE: PROOF OF CONCEPT
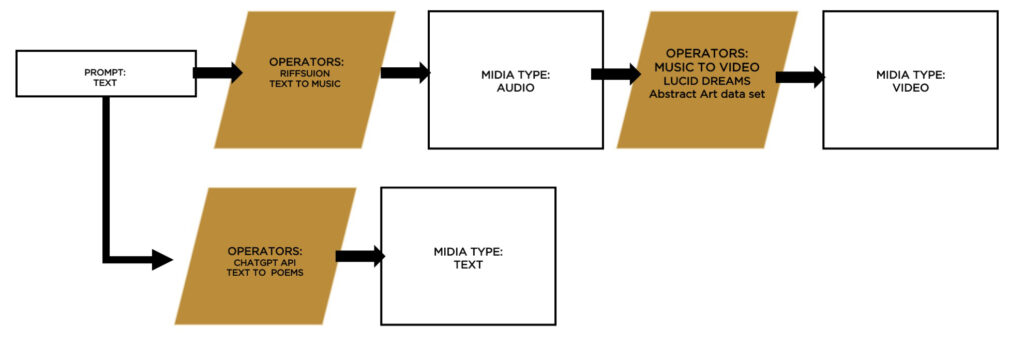
Our proof-of-concept experiment, leveraging the synergy of generative models such as Lucid Sonic Dreams, Riffusion, and ChatGPT API, marks a significant stride in creative technology. It demonstrates a fluid translation of text to varied outputs like images, audio, and video through an interconnected graph of models. This foundational work has now set the stage to extend the experiment into the realm of the metaverse, potentially opening uncharted territories for creative exploration and interaction in immersive virtual environments. [Figure 5]

Early Experimentation: Multimodal Generative Model Flowchart.
This diagram depicts the transformational journey from a textual prompt to a lyrical poem using the ChatGPT API, which then inspires a musical piece via Riffusion’s text-to-music capabilities. Subsequently, the generated audio serves as a foundation for creating a visual experience through Lucid Dreams’ music-to-video operation, culminating in an abstract art video. This illustrates the AI’s ability to traverse and transmute across different media types, embodying the essence of multimodal generative creativity.
– Lucid Sonic Dreams: Generates video visualizations from music. The visualization can be synchronized to the music’s percussive and harmonic elements. By default, it uses NVLabs StyleGAN2-ada, with pre-trained models lifted from Justin Pinkney’s consolidated repository. Custom weights and other GAN architectures can be used as well.[Pollinations.AI 2023] – source: (https://github.com/pollinations/lucid-sonic-dreams-pytorch#lucid-sonic-dreams).
-Riffusion: Generates riffs (short musical phrase) using stable diffusion v1.5 fine tuned to generate audio spectrogram images which are later converted to audio clips. [Forsgren and Martiros 2022]
Source: (https://github.com/riffusion).
-ChatGPT API [OpenAI 2023]: (https://openai.com/blog/introducing-chatgpt-and-whisper-apis).
9 CONCLUSION
Our study illustrates the transformative impact of multi-modal generative models on art, heralding a new era in the interplay between artificial intelligence and artistic expression. Grounded in empirical observation, our research delves into the dynamic roles of ’artist-observer’, ’art object’, and ’user’ in the AI-influenced art world. We utilized innovative tools and models to understand these evolving roles. MidJourney, a sophisticated generative tool designed to produce images from textual prompts, played a pivotal role in showcasing the transformative role of AI in art creation and interpretation. Alongside this, we employed Lucid Sonic Dreams and Riffusion—models that translate audio and music into dynamic visual representations and textures, respectively. The ChatGPT API was integrated for its advanced natural language processing capabilities, contributing to our understanding of AI’s impact on the digital art realm. The philosophical underpinnings of Wittgenstein and Foucault provide a critical framework for our study, offering insights into the changing nature of communication and interpretation in the digital art realm shaped by AI.
Our research draws a compelling parallel between AI algorithms and the ’DNA’ of digital art, illustrating how these algorithms guide the evolution and transformation of art, much like DNA does in biological life. This analogy underscores the complexity and adaptability of AI in driving the creation and diverse perceptions of digital art.
The broader implications of our findings are profound, particularly concerning the vast data influx in digital artistry. Our empirical analysis highlights the critical role of data in shaping the authenticity, diversity, and originality of AI-generated art.
This underscores the importance of ongoing academic research, especially in the meticulous curation of datasets, to understand and guide the impact of data selection on artistic outputs. In conclusion, our study not only redefines traditional art paradigms but also opens new avenues for future research into the intricate relationship between technology and art. It emphasizes the potential of multi-modal generative models to forge new territories in artistic expression, impacting the creation and interpretation of art in profound ways. Standing at the forefront of a digital art revolution, our research underscores the importance of ongoing academic exploration, offering critical insights into the evolving nature of creativity and art in the age of AI.



